Titanic編
はじめに
このチュートリアルでは、Kaggleで公開されているデータを利用して、予測データを作成してみます。Kaggleのデータを利用するので、Kaggleにサブミットするところまでおこなっていきます。
Kaggleとは
Kaggleは世界的なデータサイエンスのコミュニティで、分析用のデータセットを公開したり、予測モデルを探求したり、精度を競い合ったりするような場を提供するプラットフォームであり、会社でもあります。Kaggleに関する情報は検索すれば見つかるので、そちらを参照してください。
今回は、その中で入門データであるタイタニック(Titanic)を用いて、生存予測を行います。Kaggleからのデータ取得をするためには、Kaggleにログインする必要があるので、ユーザー登録してあるものとして話を進めます。
Titanicデータ
https://www.kaggle.com/c/titanic/data にアクセスして、train.csvとtest.csvをダウンロードしてください。
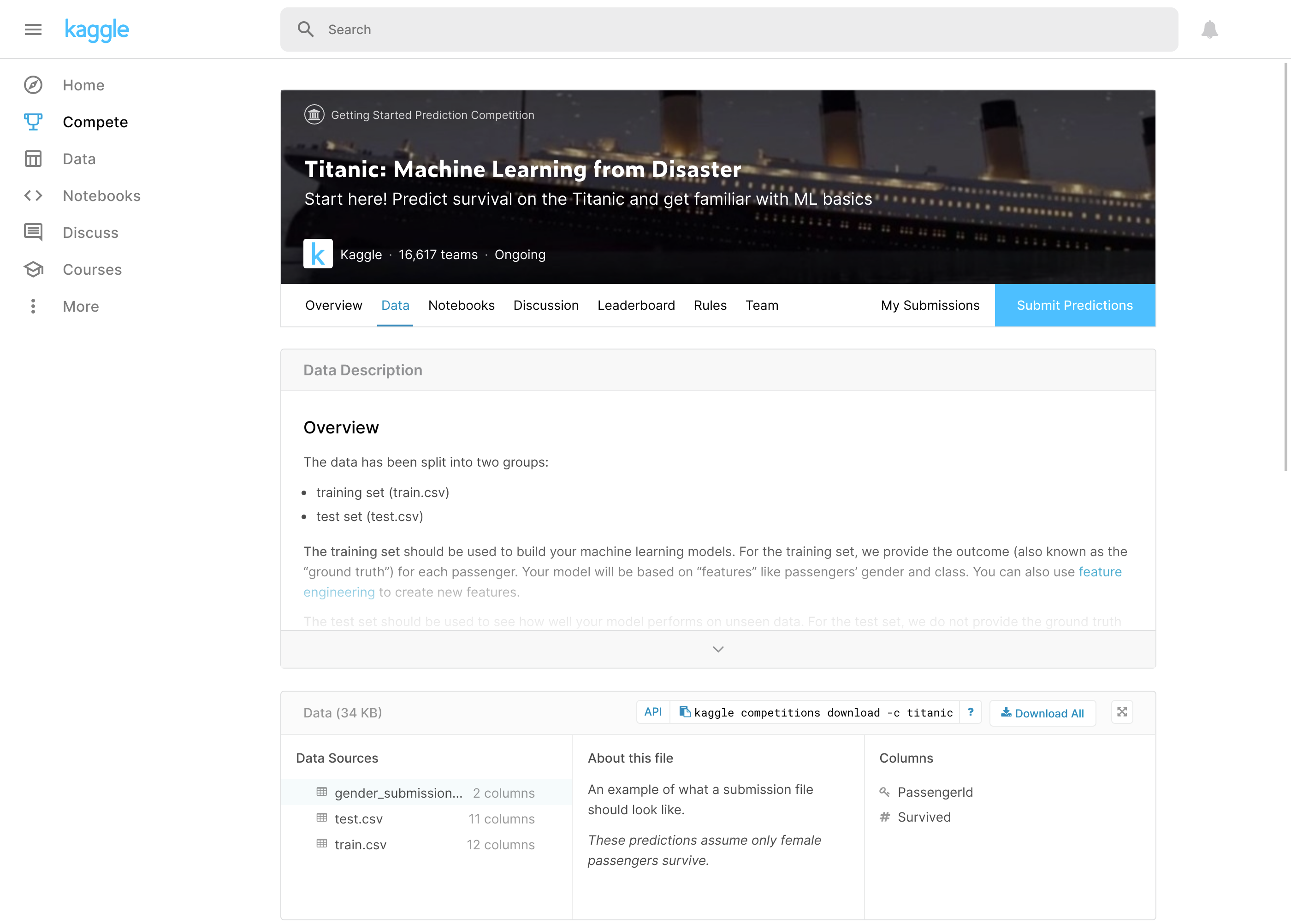
train.csvが学習用データで、test.csvはテスト用データです。テスト用データの方には生存かどうかの(Survived列)が含まれていません。
Fioneで予測データ作成
起動
Fioneの起動に必要な設定等はクイックスタートを参照してください。今回は、Fione 13.8.0を利用します。
$ git clone https://github.com/codelibs/docker-fione.git -b v13.8.0
$ cd docker-fione/compose
$ docker-compose upプロジェクトの作成
ブラウザで http://localhost:8080/admin/easyml/ にアクセスして、fioneユーザーでログインします。 デフォルトのパスワードはfioneです。
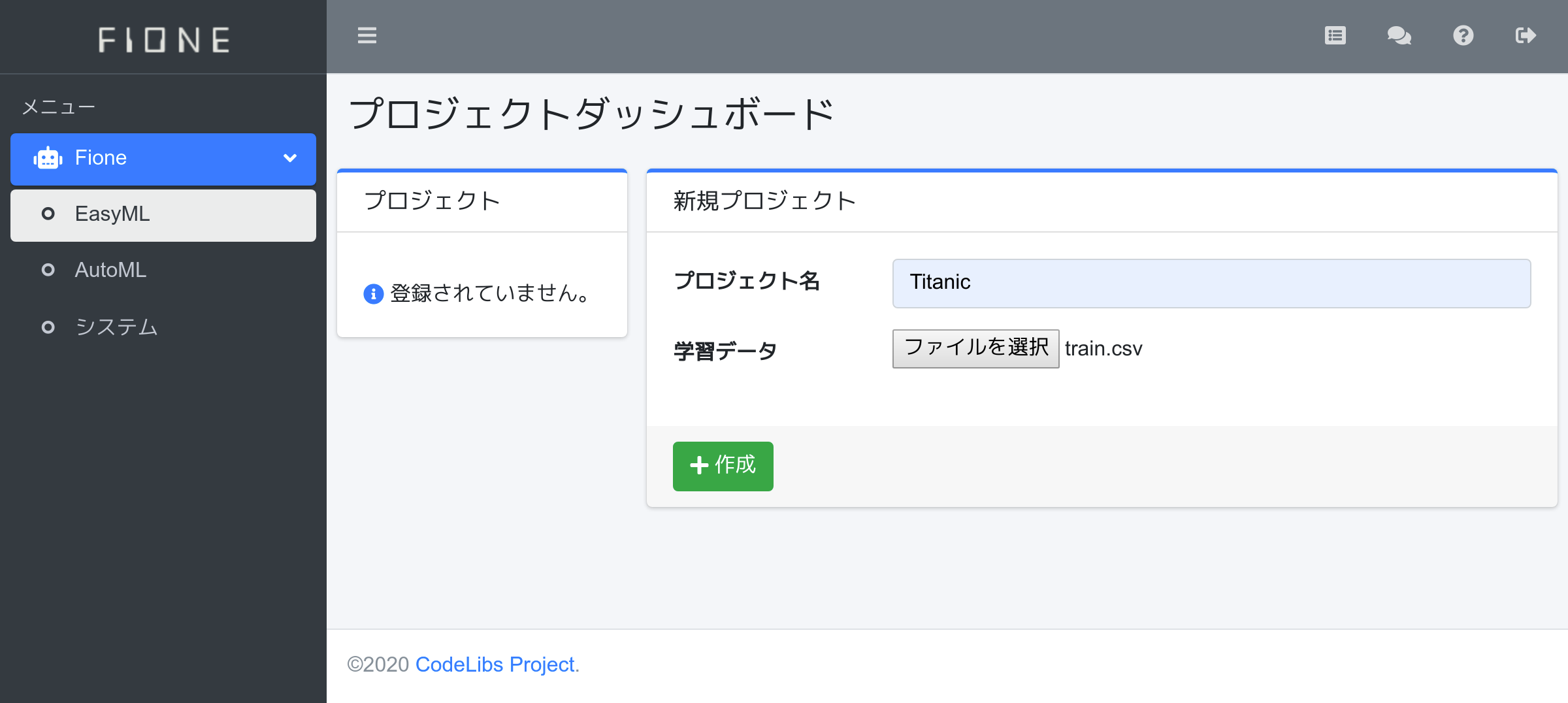
fioneユーザーでログインすると、EasyMLのプロジェクトダッシュボードが表示されます。プロジェクト名にTitanic、学習データにtrain.csvを指定して、作成ボタンを押下してください。
学習
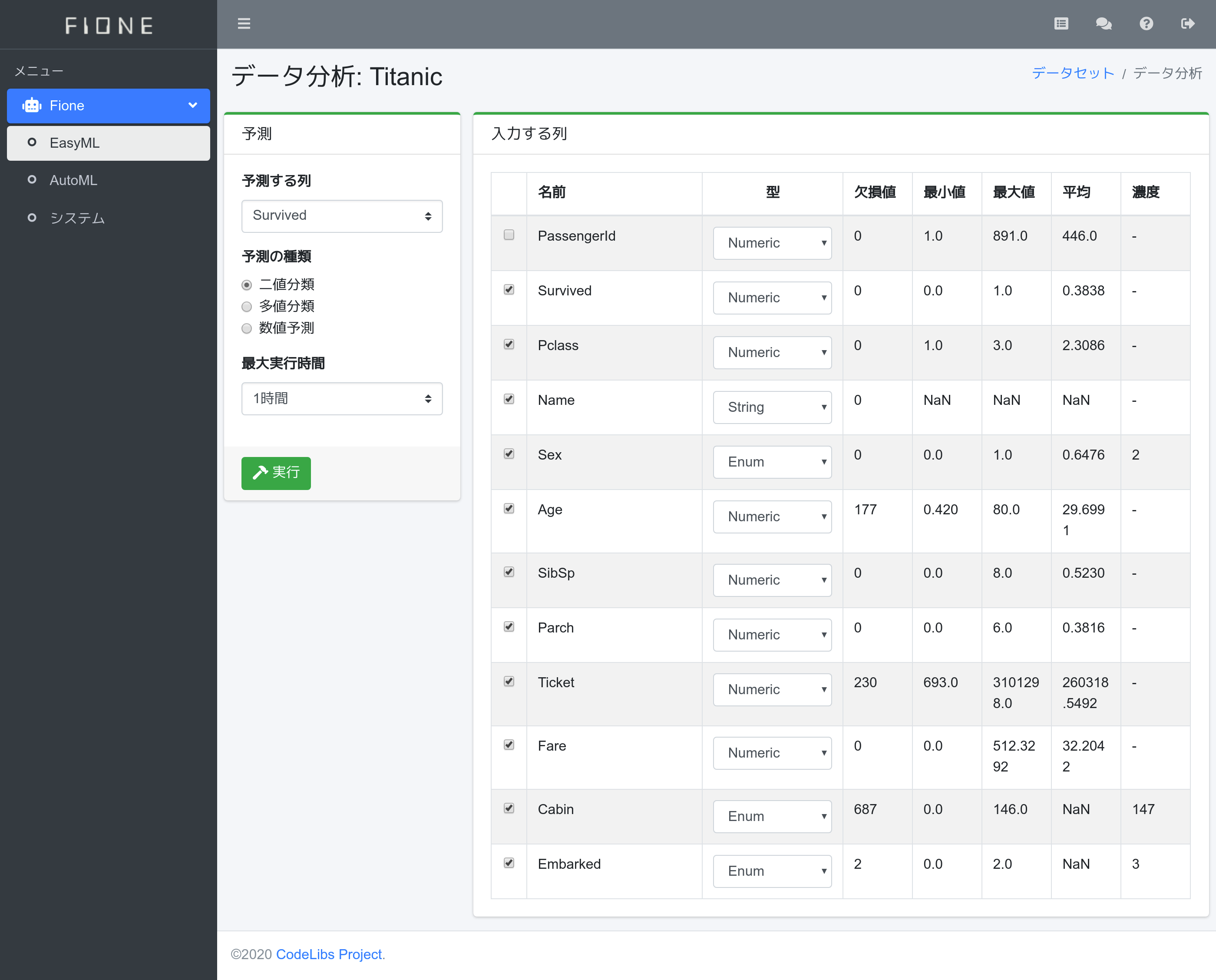
train.csvの読み込みが終わると、データ分析が表示されます。今回の予測対象はSurvived列なので、左側の予測領域で予測する列にSurvivedを選択します。Survivedは0または1の二値の予測なので、予測の種類には二値分類を選択します。最大実行時間はどれだけ時間で計算するか?なので、今回は1時間を選択して、1時間の計算を行います。実行ボタンを押下して、計算を開始します。
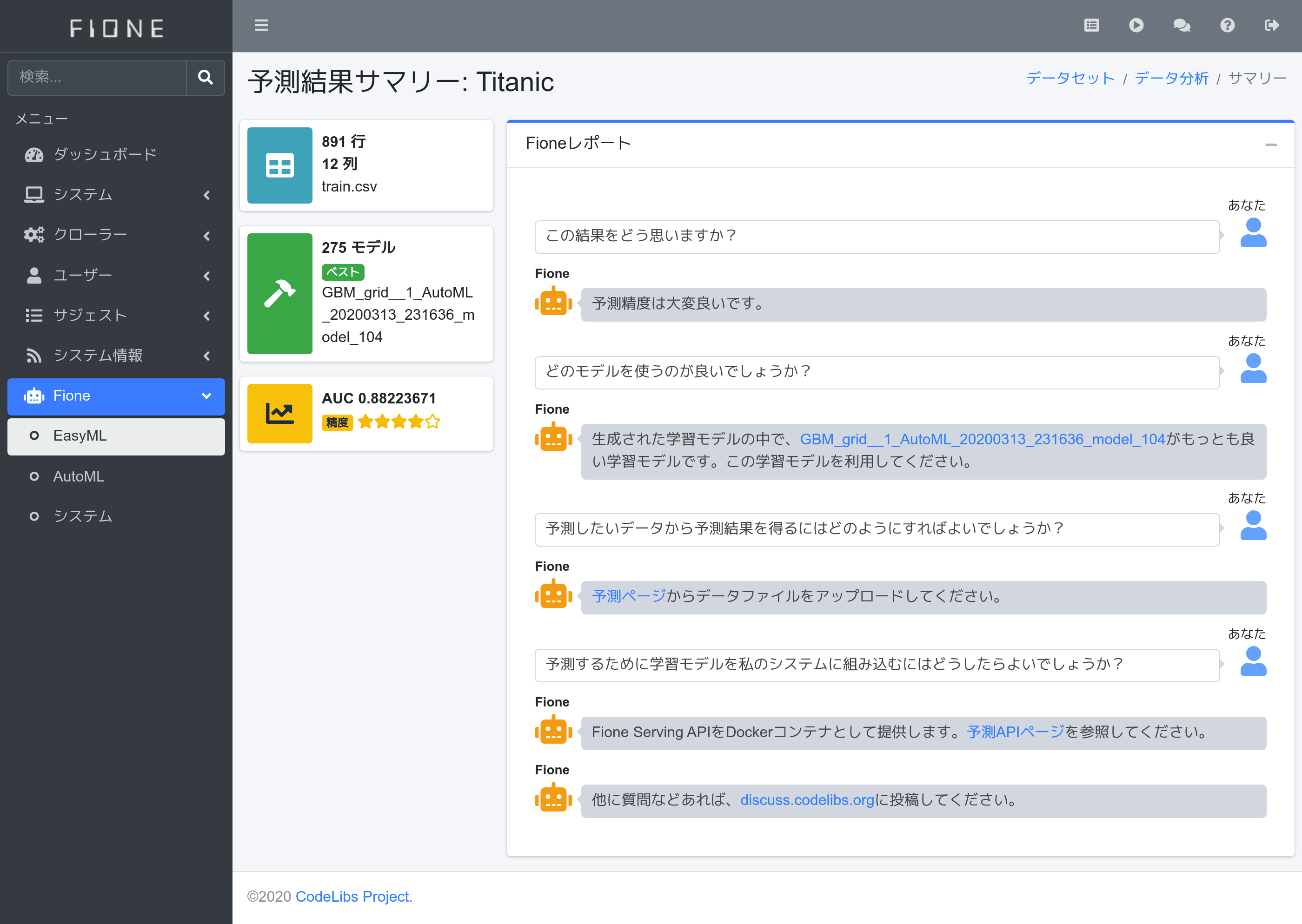
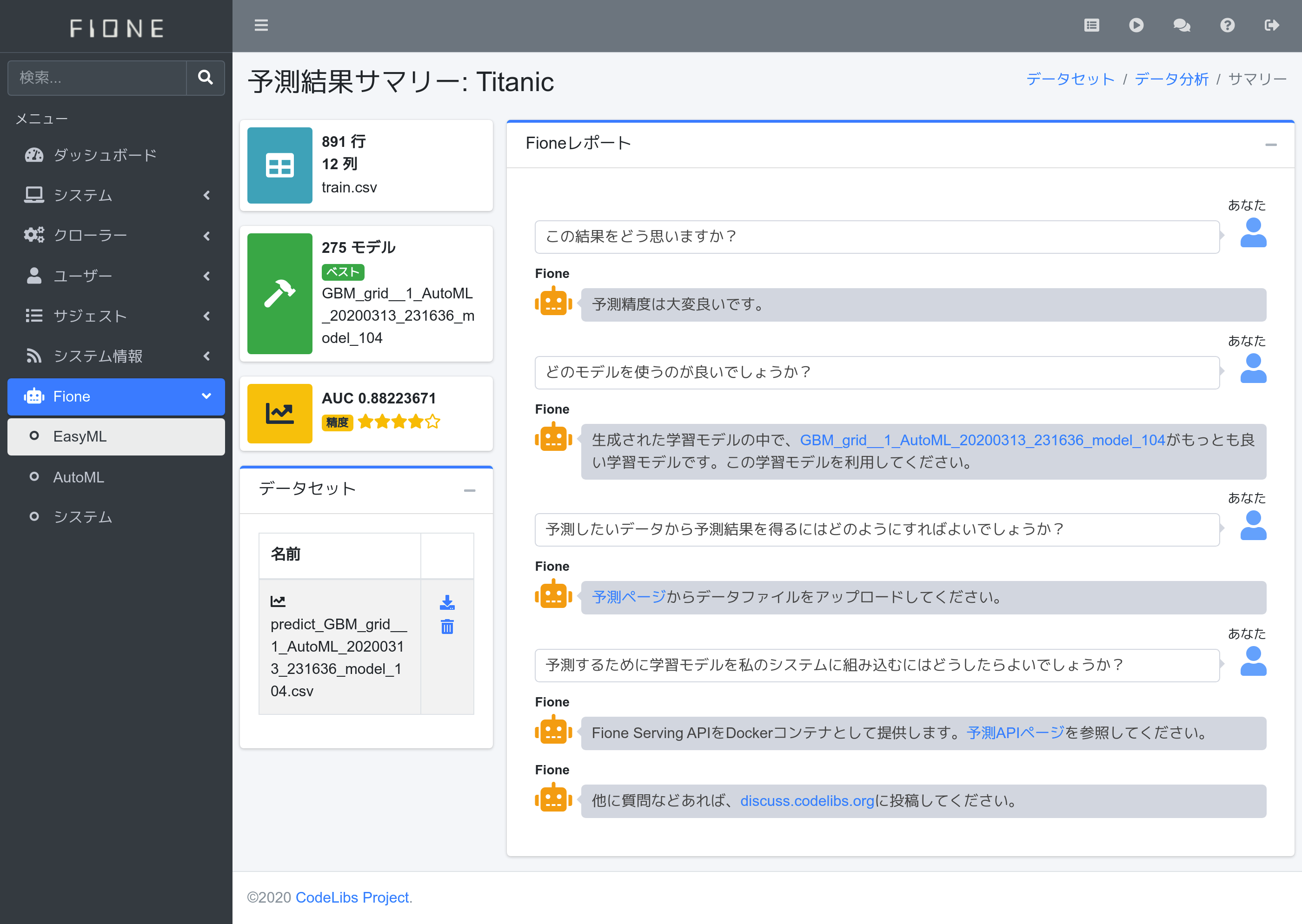
計算が終わるまたは1時間後、予測結果サマリーが表示されます。今回は275モデルを作成して、GBM gridの結果が良いようです。作成するモデル数などは実行環境に依存します。
予測データの作成
テスト用データtest.csvから予測データを作成しましょう。予測結果サマリーのFioneくんが「予測ページからデータファイルをアップロードしてください。」と言ってますので、その予測ページのリンクを押下します。
新規予測ページが表示されます。予測するデータにtest.csvを指定します。KaggleにサブミットするデータはIDと予測値だけのデータが必要なので、今回は出力する列の中でPassengerIdだけを選択します。入力後、アップロードボタンを押下します。
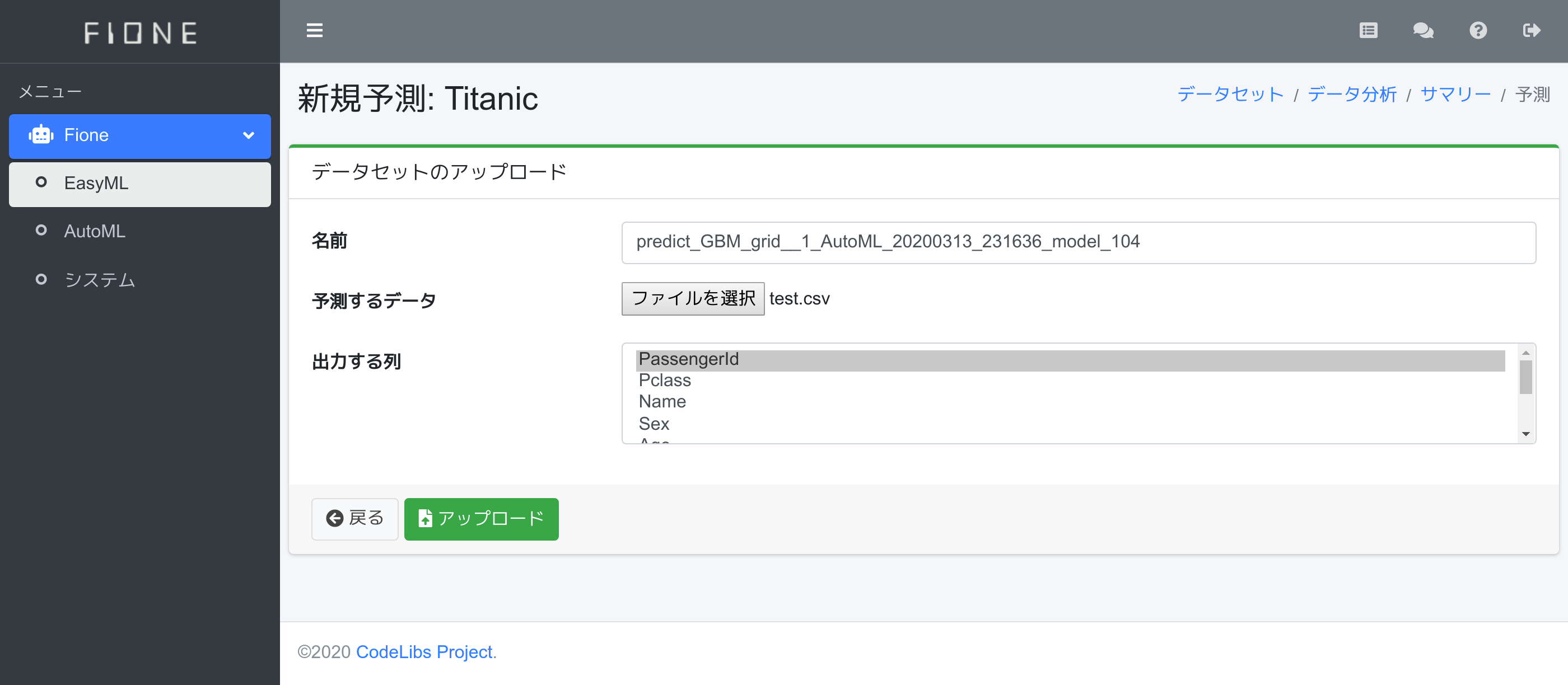
予測データ作成が完了すると、予測結果サマリーに戻ります。データセット領域が表示されるので、predict_〜.csvファイルをダウンロードします。
予測結果の提出
Kaggleに戻り、https://www.kaggle.com/c/titanic/submit を表示します。Step 1のところにpredict_〜.csvを指定して、コメントがあればStep 2のテキスト欄に入力して、Make Submissionボタンを押下します。
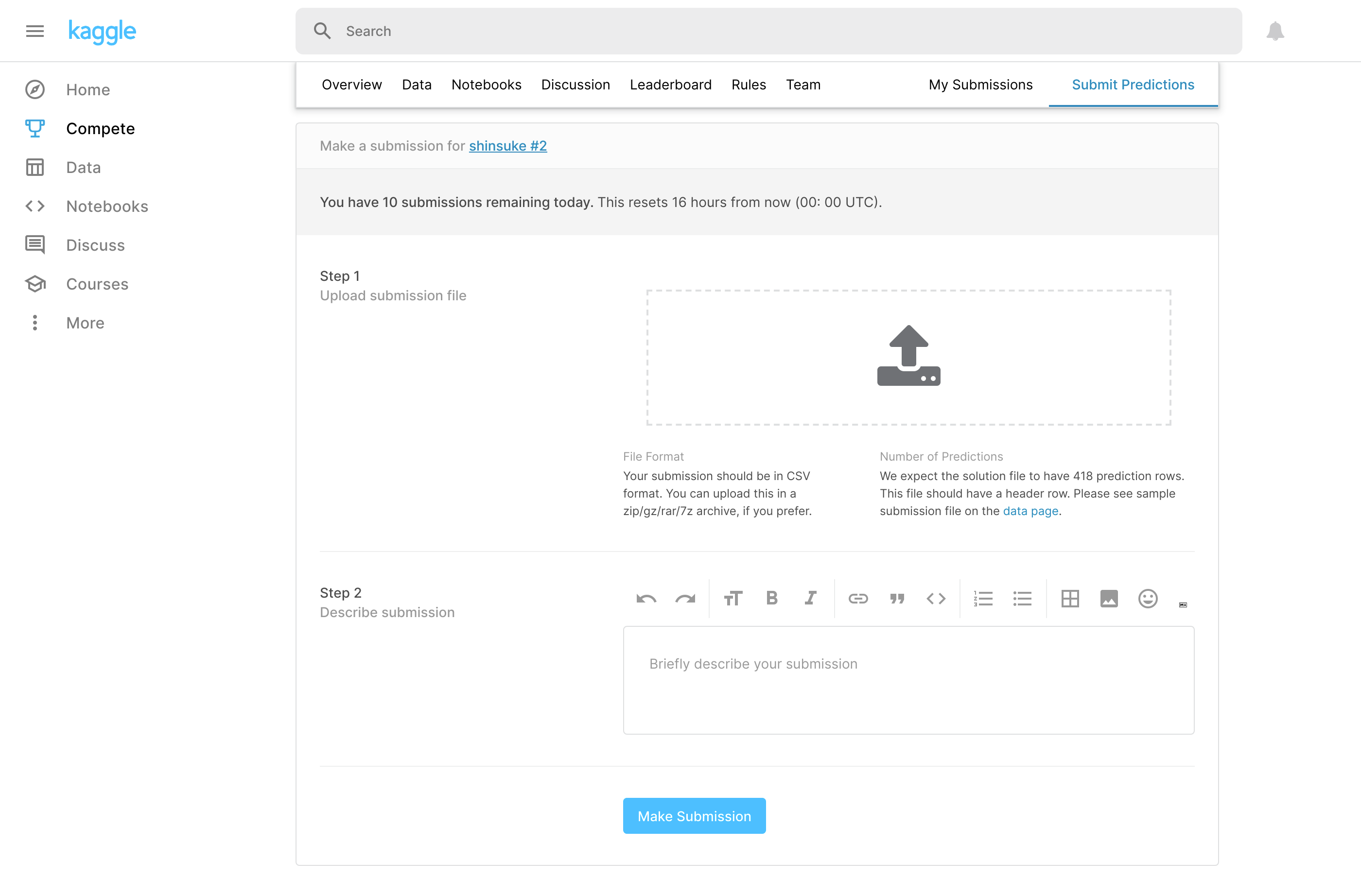
問題がなければ、My Submissionsでアップロードした結果を確認することができます。
まとめ
今回は2クラス分類問題の予測モデルを作成して、Kaggleに結果をアップロードする方法を紹介しました。(ほぼ何も考えずに)データをFioneに渡すだけで、必要な予測結果が取得できることを紹介できたと思います。予測結果サマリーから予測API化も簡単にできるので、予測したいデータがあれば同様に、予測結果またはAPIなどで利用できると思います。